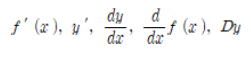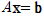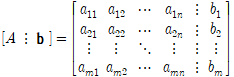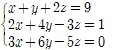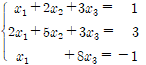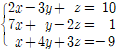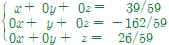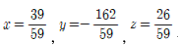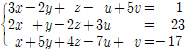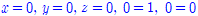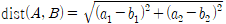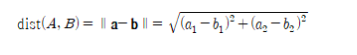✔︎ 순열과 조합
- 순열(permutation): 순서를 고려하여 나열하는 경우의 수
- nPk : 서로 다른 n개에서 k개를 택하여 순서대로 나열한 순열의 수
- nPk = n(n-1)…(n-k+1) (k≤n)
- k = n 일 때 nPn = n(n-1)…2•1 = n!
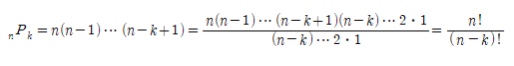
예제 1. 1부터 9까지의 숫자 중에서 서로 다른 3개를 선택하여 3자리 수를 만들려고 한다. 만들 수 있는 자연수의 개수를 구하시오.
풀이) ₉P₃ = 9 x 8 x 7 = 504
factorial(9)/factorial(6)504
- 조합(combination): 순서와 상관없이 선택하는 경우의 수
- 예를 들어, 1, 2, 3, 4, 5가 적힌 5장의 카드에서 세 장을 택하는 경우의 수는 5x4x3 / 3! = 10 이다.
- nCk : 서로 다른 n개에서 k개를 택하는 조합의 수

예제 2. 500개의 넥타이로부터 5개의 넥타이를 택하는 방법의 개수

factorial(500)/(factorial(5)*factorial(495))binomial(500, 5) # binomial(n, k) 서로 다른 n개에서 k개를 택하는 조합의 수255244687600
- 만일 중복을 허락한다면 다음과 같이 중복순열과 중복조합을 계산할 수 있다.
- 중복순열(repeated permutation): 서로 다른 n개에서 중복을 허용하여 k개를 택하여 순서대로 나열한 경우의 수

- 중복조합(repeated combination): 서로 다른 n개에서 중복을 허용하여 (순서없이) k개를 택하는 경우의 수

예제 3. 숫자 1, 2, 3, 4, 5 중에서 중복을 허락하여 세 개를 택해 일렬로 나열하여 만든 세 자리의 자연수가 5의 배수인 경우의 수를 구하시오.
풀이) 일의 자리를 5로 고정시키면 되므로, 나머지 두 자리를 1, 2, 3, 4, 5 중에서 중복을 허락하여 나열하는 경우의 수와 같다. 따라서 다음을 얻는다.

예제 4. 4명의 사람이 A, B, C 중 한 명에게 무기명으로 투표를 할 때, 나올 수 있는 경우의 수를 구하시오.
풀이) 4명이 무기명으로 투표하는 방법은 AAAA, AAAB, ..., BCCC, CCCC 이므로

✔︎ 확률
- 확률(probability): 특정 사건(event)이 일어날 가능성을 0과 1 사이의 값으로 나타낸 것
- 확률이 0: 사건이 절대로 일어날 수 없음, 확률이 1: 사건이 반드시 일어남.
- 표본공간(Sample Space): 사건들의 집합.
- 예를 들어, 동전 던지기의 경우 발생가능한 사건들은 {앞면, 뒷면} 으로 나타낼 수 있으며, 정육면체 주사위의 경우 {1, 2, 3, 4, 5, 6} 으로 나타낼 수 있다.
- S를 전체 사건의 집합(표본공간)이라 하고, A를 특정 사건의 집합이라 하자. 그러면 사건 A가 일어나는 가능성을 수로 나타낸 확률 P(A)는 A가 일어나는 경우의 수 n(A)를 전체 경우의 수 n(S)로 나누어서 구한다.
(1) 수학적 확률

(2) 기하학적 확률

(3) 통계적 확률과 대수의 법칙(Law of large number)
n번의 시행 동안, 특정 사건 A가 일어난 횟수가 k번이면, A의 통계적 확률을 k/n라 말할 수 있다. 그러나 시행 횟수 n이 충분히 커지면 통계적 확률은 수학적 확률과 같아진다.

확률은 다음 성질을 만족한다. 사건 A의 확률을 P(A)라 하면
① 표본공간 S에서 임의의 사건 A에 대하여 0 ≤ P(A) ≤ 1
② 표본공간 S에 대하여 P(S) = 1 (표본공간 전체의 확률은 1)
③ 공사건 ⦰에 대하여 P(⦰) = 0
④ 두 사건 A, B가 동시에 발생하지 않는 배반사건이면 P(A∪B) = P(A) + P(B)
⑤ 사건 A가 일어나지 않는 경우를 A 여집합이라고 하면

예제 5. 박스 안에 빨간 공 6개와 파란 공 4개가 들어 있다. 처음 빨간 공을 꺼내고, 두 번째 파란 공을 꺼낼 확률은 다음과 같다.

factorial(6)*factorial(4)/factorial(10)1/210
예제 6. R 명령어로 동전 한 개를 10회 던져 보고, 뒷면의 수와 앞면의 수를 기록해 보자.
coin = sample(c("뒤","앞"), 10, replace = TRUE) # 10회 반복
coin[1] "뒤" "뒤" "뒤" "앞" "뒤" "뒤" "앞" "뒤" "뒤" "뒤"
위의 코드에서 coin 대신에 table(coin) 명령어를 사용하면 다음과 같이 표로 나타내준다.
coin = sample(c("뒷면","앞면"), 100, replace = TRUE) # 10회 반복
table(coin)coin
뒷면 앞면
54 46
*시행의 횟수를 아주 크게 늘려 가면, 앞서 대수의 법칙에서 설명한 바와 같이 뒷면과 앞면이 나오는 확률이 ½ (수학적 확률)로 수렴함을 확인할 수 있다.
예제 7. 1000개의 제품 중에 불량품이 3개 있다. 이 제품 중에서 10개의 제품을 구입했을 때 다음 확률을 구하시오.
(1) 구입제품 중 불량품이 한 개도 없는 경우
(2) 구입제품 중 불량품이 적어도 한 개 이상 있는 경우
풀이 1) 1000개의 제품 중에 10개의 제품을 선택하는 경우의 수는 ₁₀₀₀C₁₀. (1) 불량품이 한 개도 없는 경우는 정상 제품인 997개에서 10개를 모두 선택하고, 불량품 3개에서는 하나도 선택하지 않는 경우밖에 없으므로 그 경우의 수는 ₉₉₇C₁₀x₃C₀이다. R코드를 이용하여 계산하면 다음과 같다.
# 모두 불량품이 아닐 확률
choose(997, 10)* choose(3, 0)/ choose(1000, 10)[1] 0.9702695
풀이 2) 불량품이 적어도 한 개 이상 있을 확률은, 1에서 불량품이 한 개도 없는 확률을 빼면 된다.

# 셀의 오른쪽 하단의 Language를 R로 변경하여 실행하세요.
# 적어도 불량품이 1개 이상 있을 확률
1 - choose(997, 10)*choose(3, 0)/choose(1000, 10)
[1] 0.02973045
✔︎ 조건부확률
- 어떤 사건 A가 일어났다는 조건 하에서 사건 B가 일어날 확률을 사건 A에 대한 사건 B의 조건부확률(conditional probability)이라고 한다.

- 곰셈정리(관계식)

- 일반적으로 사건 A₁, A₂, …, An에 대하여 다음이 성립한다.

✔︎ 베이즈 정리
- 베이즈 정리(Bayes’ theorem)는 주어진 조건에서 어떠한 현상이 실제로 나타날 확률을 구하는 방법으로, 불확실성 하에서 의사결정 문제를 수학적으로 다룰 때 중요하게 이용된다.
- 사전확률(prior probability)은 관측자가 이미 알고 있는 사건으로부터 나온 확률. P(A)는 A에 대한 사전확률.
- 사후확률(posteriori probability)은 어떤 특정사건이 이미 발생하였는데, 이 특정사건이 나온 이유가 무엇인지 불확실한 상황을 식으로 나타낸 것. P(A | B). 여기서 B는 이미 일어난 사건이고, 사건 B를 관측한 후에 그 원인이 되는 사건 A의 확률을 따졌다는 의미로 사후확률이라고 정의.
- 베이즈 정리는 사전확률과 사건으로부터 얻은 자료를 사용하여 사후확률을 추출해내는 것. 즉, 사전확률과 사후확률의 관계를 조건부 확률을 이용하여 계산하는 이론.
{A₁, A₂, …, An}이 표본공간 S의 분할(partition)을 이룬다고 하자. 그러면 임의의 사건 B에 대하여 다음이 성립한다.

이때 Aᵢ ⋂ B (𝑖 = 1, 2, …, n)는 서로 배반(exclusive)이다. 따라서

한편, 확률의 곱셈정리로부터 아레 전확률 공식(Law of Total Probability)을 얻을 수 있다.

또한, 임의의 𝑖에 대한 조건부확률 P(Aᵢ | B) = P(A⋂B) / P(B)에 P(Aᵢ | B) = P(Aᵢ)P(B | Aᵢ)와 전확률 공식을 대입하면 다음 식을 얻을 수 있는데 이를 베이즈 정리(Bayes' theorem)라고 한다.

여기서 P(Aᵢ)를 사건 Aᵢ의 사전확률, P(Aᵢ | B)를 사건 Aᵢ의 사후확률이라고 한다.
예제 8. 3대의 가계 A, B, C가 각각 이 공장의 생산품 전체의 50%, 30%, 20%를 생산한다. 그리고 이들 기계가 불량품을 생산할 비율은 각각 4%, 3%, 2%이다. 한 제품을 임의로 선택할 때 그 제품이 불량품일 확률을 구하여라. 또한 불량품이 가계 C에 의하여 생산될 확률을 구하시오.
풀이) 구입한 1개의 제품이 기계 C로 생산된 제품인 사건을 C로 나타내고, 그것이 불량품이라는 사건을 X로 나타내면,
- 제품을 생산하는 사건: A∪B∪C = S 이고, P(A) = 0.5, P(B) = 0.3, P(C) = 0.2
- 불량품을 생산하는 사건: X = (A⋂X)∪(B⋂X)∪(C⋂X)
- 불량품을 생산하는 확률: P(X | A) = 0.04, P(X | B) = 0.03, P(X | C) = 0.02
- 전확률 공식에 대입: P(X) = P(A)P(X | A) + P(B)P(X | B) + P(C)P(X | C) = 0.5x0.04+0.3x0.03+0.2x0.02 = 0.033
따라서 베이즈 정리에 의하여 불량품 중 기계 C가 생산한 제품이 불량품일 확률은 다음과 같다.

✔︎ 확률변수
- 어떤 값을 취하느냐가 확률적으로 결정되는 변수. 표본 공간의 모든 표본에 대해 어떤 실수 값을 대응시킨(할당한) 것.

✔︎ 이산확률분포
- 확률변수 X가 연속적이지 않은 값 𝒙₁, 𝒙₂, …, 𝒙n을 취할 때, X를 이산확률변수라고 하고, 각각의 𝒙ᵢ에 대하여 X = 𝒙ᵢ일 확률 P(X = 𝒙ᵢ)을 할당한 것을 이산확률분포라고 한다.

- 이산확률변수 X가 𝒙₁, 𝒙₂, …, 𝒙n의 값을 취할 때 확률 P(X = 𝒙ᵢ)을 대응시키는 함수 𝑓(𝒙)를 확률변수 X의 확률질량함수(probability mass function)라 한다.

- 확률질량함수는 다음과 같은 성질이 있다.

✔︎ 연속확률분포
- 확률변수 X가 어떤 범위에 속하는 모든 실수를 취할 때, X를 연속확률변수라 한다.
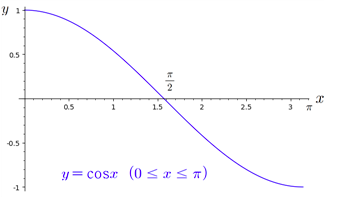
- 연속확률변수 X에 대하여 함수 𝑓(𝒙)가 다음의 성질을 만족하면 𝑓(𝒙)를 X의 확률밀도함수(probability density function)라 한다.
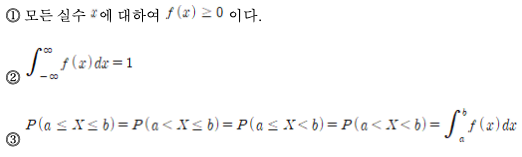
따라서 확률 P(a≤X≤b)는 아래 그림에서 색깔로 표시한 부분의 넓이와 같다. 이때 구간의 끝점(a, b)이 범위에 포함되는지의 여부는 관계가 없다.

'◦ Machine Learning > Mathmatics' 카테고리의 다른 글
| [기초수학] 경사하강법과 최소제곱문제의 해 (1) | 2021.01.16 |
|---|---|
| [기초수학] 극대, 극소, 최대, 최소 (0) | 2021.01.11 |
| [기초수학] 극한과 도함수 (0) | 2021.01.11 |
| [기초수학] 정사영과 최소제곱문제 (0) | 2021.01.09 |
| [기초수학] 선형연립방정식의 해집합 (0) | 2021.01.08 |